

{kind=link}
When conversational AIs like ChatGPT, Perplexity, or Google AI Mode generate snippets or reply summaries, they’re not writing from scratch, they’re selecting, compressing, and reassembling what webpages supply. In case your content material isn’t Search engine optimisation-friendly and indexable, it gained’t make it into generative search in any respect. Search, as we all know it, is now a perform of synthetic intelligence.
However what in case your web page doesn’t “supply” itself in a machine-readable kind? That’s the place structured information is available in, not simply as an Search engine optimisation gig, however as a scaffold for AI to reliably choose the “proper details.” There was some confusion in our group, and on this article, I’ll:
- stroll by managed experiments on 97 webpages exhibiting how structured information improves snippet consistency and contextual relevance,
- map these outcomes into our semantic framework.
Many have requested me in current months if LLMs use structured information, and I’ve been repeating time and again that an LLM doesn’t use structured information because it has no direct entry to the world huge net. An LLM makes use of instruments to look the net and fetch webpages. Its instruments – normally – vastly profit from indexing structured information.
In our early outcomes, structured information will increase snippet consistency and improves contextual relevance in GPT-5. It additionally hints at extending the efficient wordlim envelope – it is a hidden GPT-5 directive that decides what number of phrases your content material will get in a response. Think about it as a quota in your AI visibility that will get expanded when content material is richer and better-typed. You’ll be able to learn extra about this idea, which I first outlined on LinkedIn.
Why This Issues Now
- Wordlim constraints: AI stacks function with strict token/character budgets. Ambiguity wastes price range; typed details preserve it.
- Disambiguation & grounding: Schema.org reduces the mannequin’s search house (“it is a Recipe/Product/Article”), making choice safer.
- Information graphs (KG): Schema typically feeds KGs that AI programs seek the advice of when sourcing details. That is the bridge from net pages to agent reasoning.
My private thesis is that we need to deal with structured information because the instruction layer for AI. It doesn’t “rank for you,” it stabilizes what AI can say about you.
Experiment Design (97 URLs)
Whereas the pattern dimension was small, I needed to see how ChatGPT’s retrieval layer really works when used from its personal interface, not by the API. To do that, I requested GPT-5 to look and open a batch of URLs from several types of web sites and return the uncooked responses.
You’ll be able to immediate GPT-5 (or any AI system) to point out the verbatim output of its inner instruments utilizing a easy meta-prompt. After accumulating each the search and fetch responses for every URL, I ran an Agent WordLift workflow [disclaimer, our AI SEO Agent] to investigate each web page, checking whether or not it included structured information and, if that’s the case, figuring out the particular schema sorts detected.
These two steps produced a dataset of 97 URLs, annotated with key fields:
- has_sd → True/False flag for structured information presence.
- schema_classes → the detected kind (e.g., Recipe, Product, Article).
- search_raw → the “search-style” snippet, representing what the AI search instrument confirmed.
- open_raw → a fetcher abstract, or structural skim of the web page by GPT-5.
Utilizing a “LLM-as-a-Choose” method powered by Gemini 2.5 Professional, I then analyzed the dataset to extract three most important metrics:
- Consistency: distribution of search_raw snippet lengths (field plot).
- Contextual relevance: key phrase and subject protection in open_raw by web page kind (Recipe, E-comm, Article).
- High quality rating: a conservative 0–1 index combining key phrase presence, fundamental NER cues (for e-commerce), and schema echoes within the search output.
The Hidden Quota: Unpacking “wordlim”
Whereas operating these checks, I seen one other refined sample, one that may clarify why structured information results in extra constant and full snippets. Inside GPT-5’s retrieval pipeline, there’s an inner directive informally often called wordlim: a dynamic quota figuring out how a lot textual content from a single webpage could make it right into a generated reply.
At first look, it acts like a phrase restrict, however it’s adaptive. The richer and better-typed a web page’s content material, the extra room it earns within the mannequin’s synthesis window.
From my ongoing observations:
- Unstructured content material (e.g., a normal weblog publish) tends to get about ~200 phrases.
- Structured content material (e.g., product markup, feeds) extends to ~500 phrases.
- Dense, authoritative sources (APIs, analysis papers) can attain 1,000+ phrases.
This isn’t arbitrary. The restrict helps AI programs:
- Encourage synthesis throughout sources fairly than copy-pasting.
- Keep away from copyright points.
- Maintain solutions concise and readable.
But it additionally introduces a brand new Search engine optimisation frontier: your structured information successfully raises your visibility quota. In case your information isn’t structured, you’re capped on the minimal; whether it is, you grant AI extra belief and extra space to characteristic your model.
Whereas the dataset isn’t but massive sufficient to be statistically vital throughout each vertical, the early patterns are already clear – and actionable.
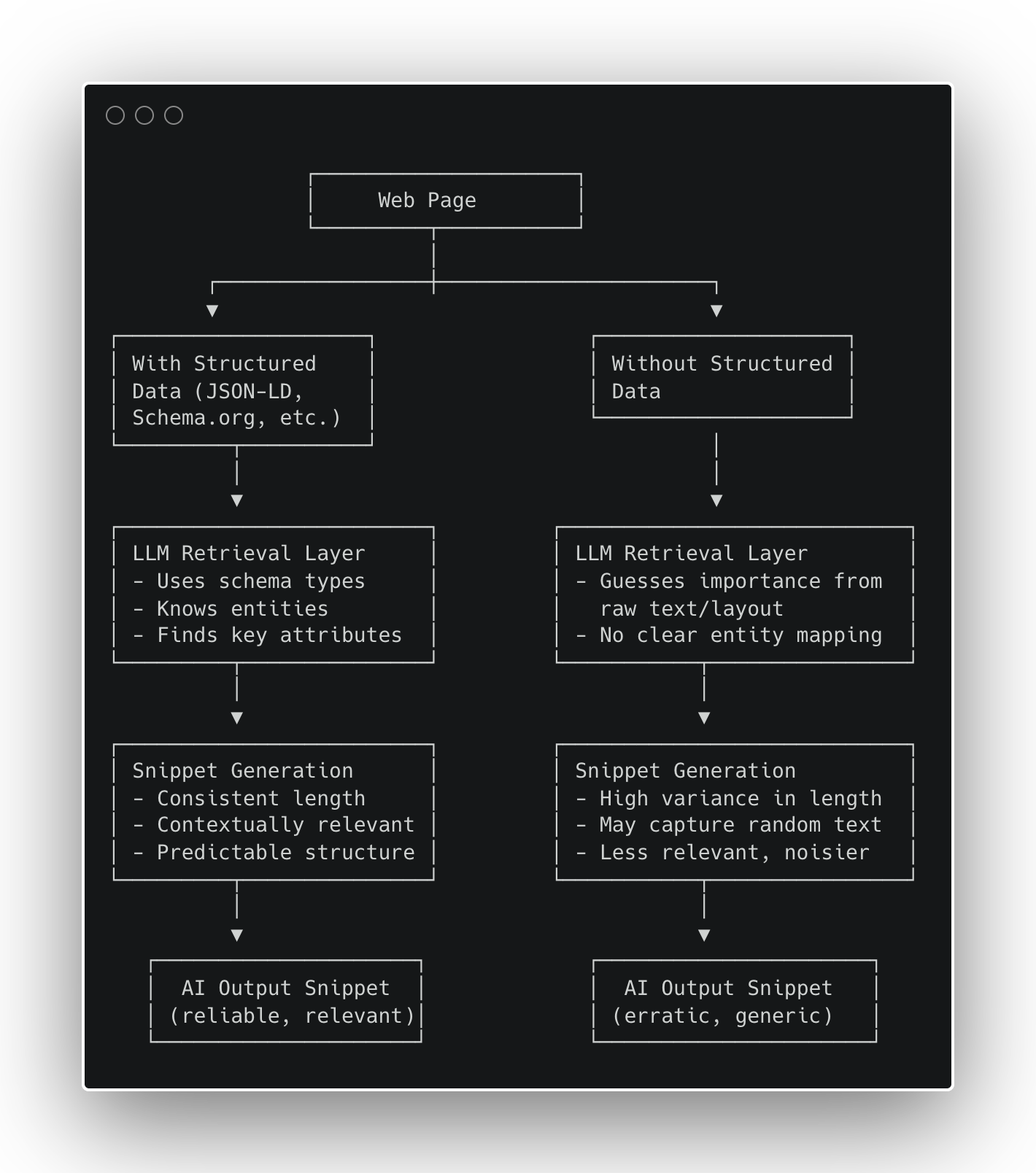 Determine 1 – How Structured Information Impacts AI Snippet Era (Picture by creator, October 2025)
Determine 1 – How Structured Information Impacts AI Snippet Era (Picture by creator, October 2025)Outcomes
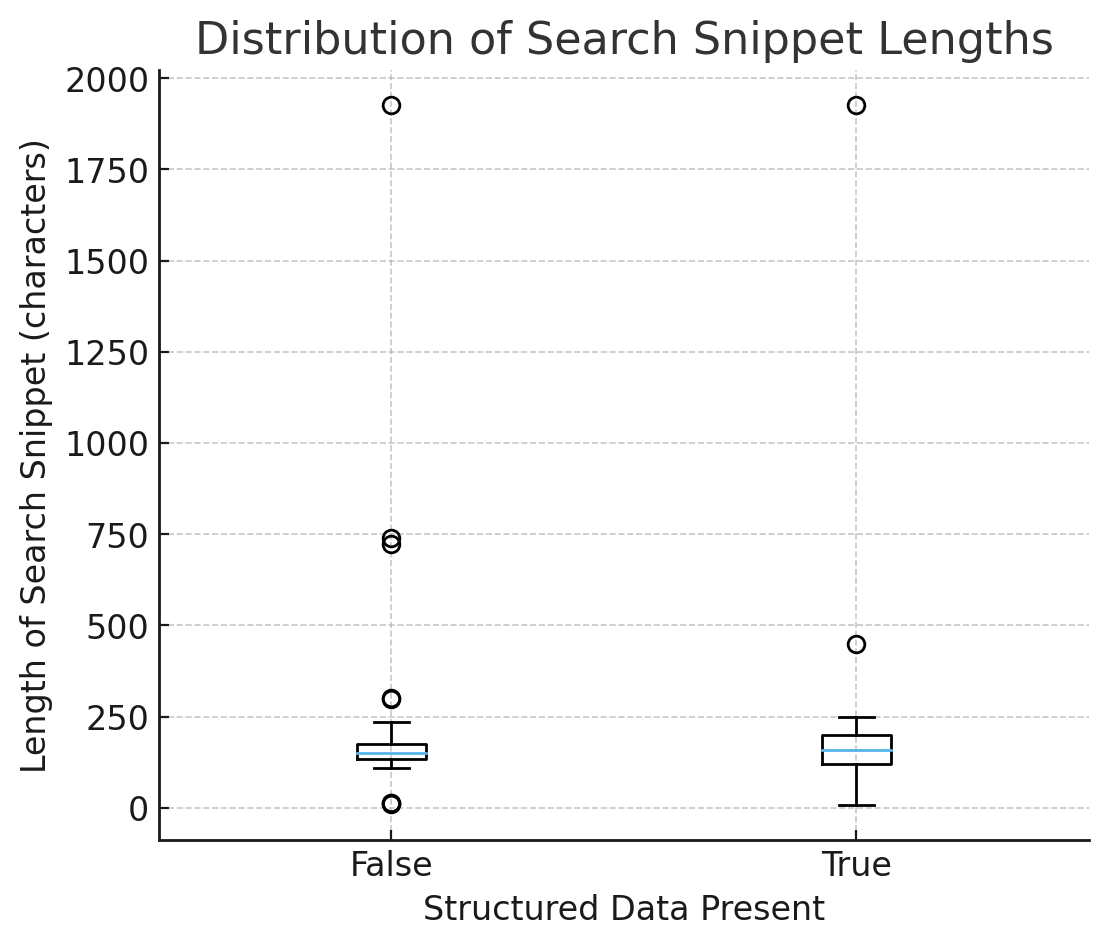 Determine 2 – Distribution of Search Snippet Lengths (Picture by creator, October 2025)
Determine 2 – Distribution of Search Snippet Lengths (Picture by creator, October 2025)1) Consistency: Snippets Are Extra Predictable With Schema
Within the field plot of search snippet lengths (with vs. with out structured information):
- Medians are related → schema doesn’t make snippets longer/shorter on common.
- Unfold (IQR and whiskers) is tighter when has_sd = True → much less erratic output, extra predictable summaries.
Interpretation: Structured information doesn’t inflate size; it reduces uncertainty. Fashions default to typed, secure details as a substitute of guessing from arbitrary HTML.
2) Contextual Relevance: Schema Guides Extraction
- Recipes: With Recipe schema, fetch summaries are far likelier to incorporate components and steps. Clear, measurable elevate.
- Ecommerce: The search instrument typically echoes JSON‑LD fields (e.g., aggregateRating, supply, model) proof that schema is learn and surfaced. Fetch summaries skew to precise product names over generic phrases like “value,” however the identification anchoring is stronger with schema.
- Articles: Small however current features (creator/date/headline extra prone to seem).
3) High quality Rating (All Pages)
Averaging the 0–1 rating throughout all pages:
- No schema → ~0.00
- With schema → constructive uplift, pushed largely by recipes and a few articles.
Even the place means look related, variance collapses with schema. In an AI world constrained by wordlim and retrieval overhead, low variance is a aggressive benefit.
Past Consistency: Richer Information Extends The Wordlim Envelope (Early Sign)
Whereas the dataset isn’t but massive sufficient for significance checks, we noticed this rising sample:
Pages with richer, multi‑entity structured information are inclined to yield barely longer, denser snippets earlier than truncation.
Speculation: Typed, interlinked details (e.g., Product + Provide + Model + AggregateRating, or Article + creator + datePublished) assist fashions prioritize and compress increased‑worth info – successfully extending the usable token price range for that web page.
Pages with out schema extra typically get prematurely truncated, possible attributable to uncertainty about relevance.
Subsequent step: We’ll measure the connection between semantic richness (rely of distinct Schema.org entities/attributes) and efficient snippet size. If confirmed, structured information not solely stabilizes snippets – it will increase informational throughput underneath fixed phrase limits.
From Schema To Technique: The Playbook
We construction websites as:
- Entity Graph (Schema/GS1/Articles/ …): merchandise, provides, classes, compatibility, places, insurance policies;
- Lexical Graph: chunked copy (care directions, dimension guides, FAQs) linked again to entities.
Why it really works: The entity layer provides AI a secure scaffold; the lexical layer gives reusable, quotable proof. Collectively they drive precision underneath thewordlim constraints.
Right here’s how we’re translating these findings right into a repeatable Search engine optimisation playbook for manufacturers working underneath AI discovery constraints.
- Ship JSON‑LD for core templates
- Recipes → Recipe (components, directions, yields, instances).
- Merchandise → Product + Provide (model, GTIN/SKU, value, availability, scores).
- Articles → Article/NewsArticle (headline, creator, datePublished).
- Unify entity + lexical
Maintain specs, FAQs, and coverage textual content chunked and entity‑linked. - Harden snippet floor
Information have to be constant throughout seen HTML and JSON‑LD; maintain crucial details above the fold and secure. - Instrument
Monitor variance, not simply averages. Benchmark key phrase/subject protection inside machine summaries by template.
Conclusion
Structured information doesn’t change the common dimension of AI snippets; it adjustments their certainty. It stabilizes summaries and shapes what they embody. In GPT-5, particularly underneath aggressive wordlim situations, that reliability interprets into increased‑high quality solutions, fewer hallucinations, and higher model visibility in AI-generated outcomes.
For SEOs and product groups, the takeaway is evident: deal with structured information as core infrastructure. In case your templates nonetheless lack strong HTML semantics, don’t leap straight to JSON-LD: repair the foundations first. Begin by cleansing up your markup, then layer structured information on prime to construct semantic accuracy and long-term discoverability. In AI search, semantics is the brand new floor space.
Extra Assets:
Featured Picture: TierneyMJ/Shutterstock